NVIDIA Chat
NVIDIA LLM API 是一個代理 AI 推理引擎,提供來自各種提供商的各種模型。
Spring AI 透過重用現有的 OpenAI 客戶端與 NVIDIA LLM API 整合。為此,你需要將 base-url 設定為 https://integrate.api.nvidia.com,選擇一個提供的 LLM 模型,並獲取其 api-key。
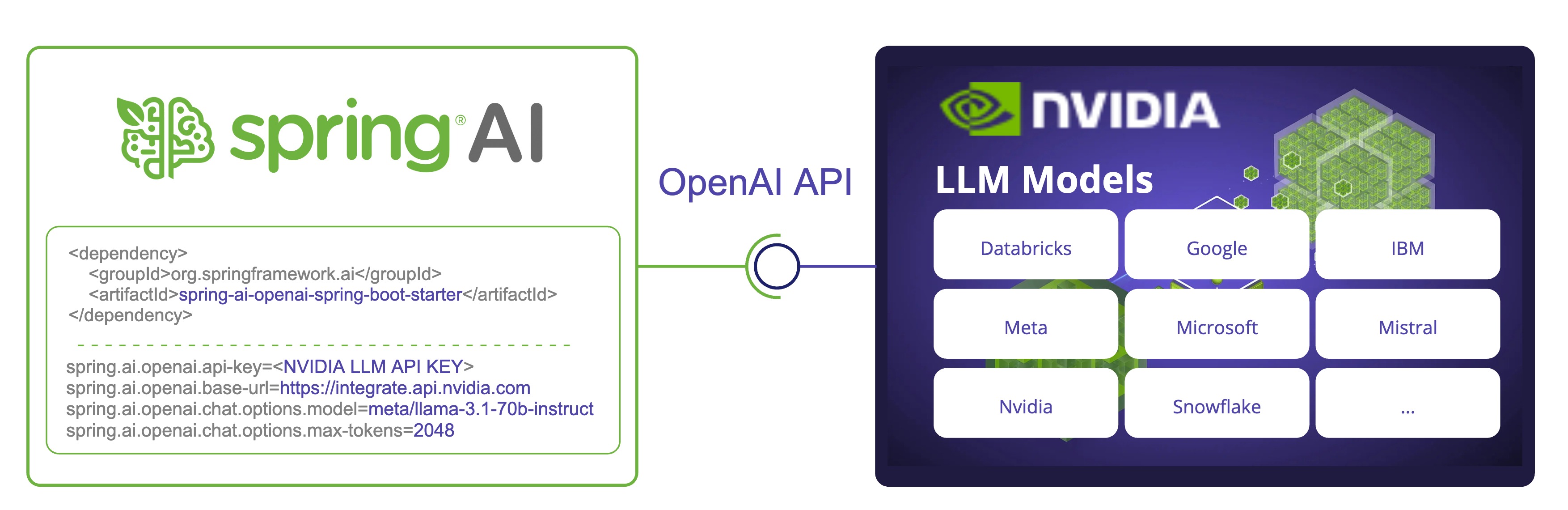
NVIDIA LLM API 要求顯式設定 max-tokens 引數,否則將丟擲伺服器錯誤。 |
請檢視 NvidiaWithOpenAiChatModelIT.java 測試,瞭解如何將 NVIDIA LLM API 與 Spring AI 結合使用的示例。
前提條件
-
建立一個擁有足夠積分的 NVIDIA 賬戶。
-
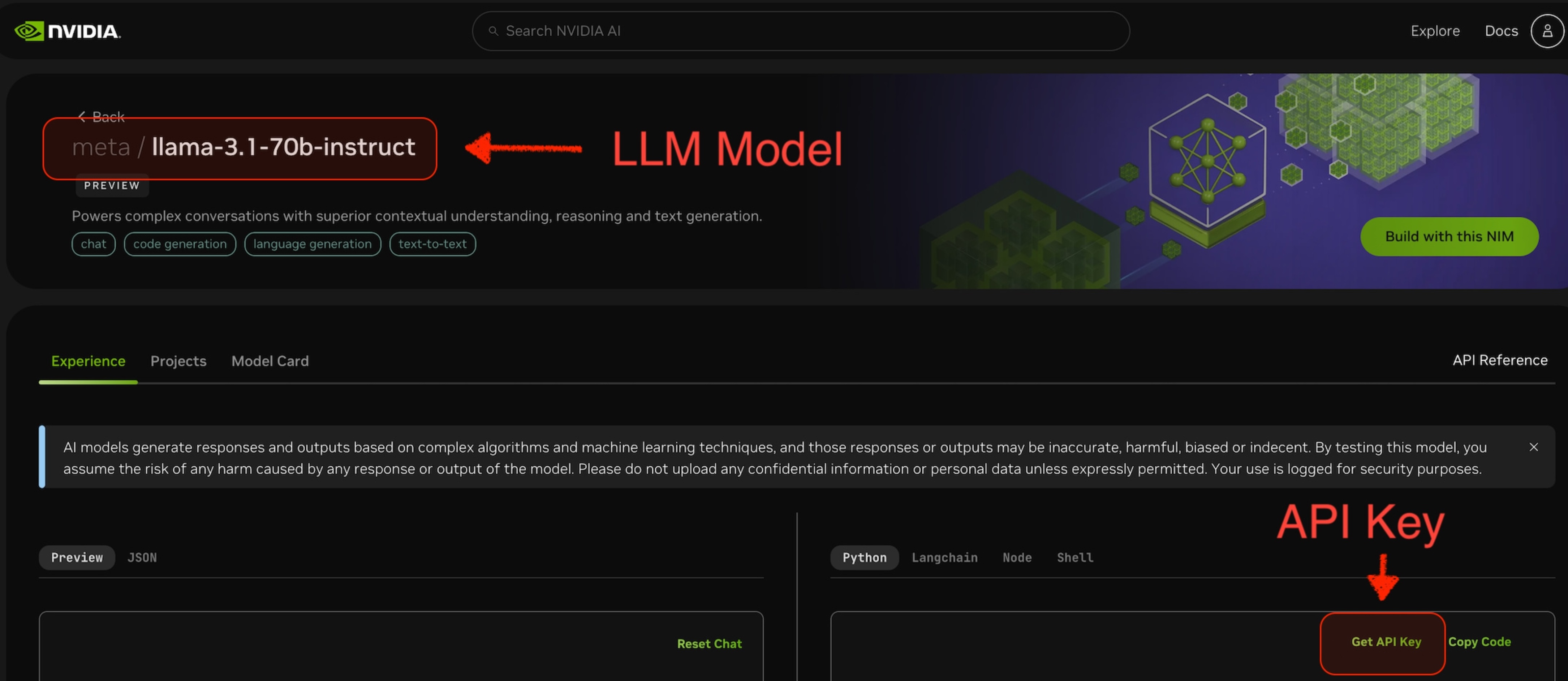
選擇一個要使用的 LLM 模型。例如,下圖中的
meta/llama-3.1-70b-instruct。 -
從所選模型的頁面,你可以獲取訪問此模型的
api-key。
自動配置
|
Spring AI 自動配置、啟動模組的工件名稱發生了重大變化。請參閱 升級說明 以獲取更多資訊。 |
Spring AI 為 OpenAI Chat Client 提供 Spring Boot 自動配置。要啟用它,請將以下依賴項新增到你的專案的 Maven pom.xml 檔案中
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>或新增到您的 Gradle build.gradle 構建檔案中。
dependencies {
implementation 'org.springframework.ai:spring-ai-starter-model-openai'
}| 請參閱 依賴項管理 部分,將 Spring AI BOM 新增到您的構建檔案中。 |
聊天屬性
重試屬性
字首 spring.ai.retry 用作屬性字首,允許您為 OpenAI 聊天模型配置重試機制。
| 財產 | 描述 | 預設值 |
|---|---|---|
spring.ai.retry.max-attempts |
最大重試次數。 |
10 |
spring.ai.retry.backoff.initial-interval |
指數回退策略的初始休眠持續時間。 |
2 秒。 |
spring.ai.retry.backoff.multiplier |
回退間隔乘數。 |
5 |
spring.ai.retry.backoff.max-interval |
最大回退持續時間。 |
3 分鐘。 |
spring.ai.retry.on-client-errors |
如果為 false,則丟擲 NonTransientAiException,並且不嘗試重試 |
假 |
spring.ai.retry.exclude-on-http-codes |
不應觸發重試的 HTTP 狀態程式碼列表(例如,丟擲 NonTransientAiException)。 |
空 |
spring.ai.retry.on-http-codes |
應觸發重試的 HTTP 狀態程式碼列表(例如,丟擲 TransientAiException)。 |
空 |
連線屬性
字首 spring.ai.openai 用作屬性字首,允許您連線到 OpenAI。
| 財產 | 描述 | 預設值 |
|---|---|---|
spring.ai.openai.base-url |
要連線的 URL。必須設定為 |
- |
spring.ai.openai.api-key |
NVIDIA API 金鑰 |
- |
配置屬性
|
聊天自動配置的啟用和停用現在透過以 要啟用,spring.ai.model.chat=openai (預設啟用) 要停用,spring.ai.model.chat=none (或任何不匹配 openai 的值) 此更改是為了允許配置多個模型。 |
字首 spring.ai.openai.chat 是屬性字首,允許您配置 OpenAI 的聊天模型實現。
| 財產 | 描述 | 預設值 |
|---|---|---|
spring.ai.openai.chat.enabled (已刪除,不再有效) |
啟用 OpenAI 聊天模型。 |
true |
spring.ai.model.chat |
啟用 OpenAI 聊天模型。 |
openai |
spring.ai.openai.chat.base-url |
可選覆蓋 spring.ai.openai.base-url 以提供特定於聊天的 URL。必須設定為 |
- |
spring.ai.openai.chat.api-key |
可選覆蓋 spring.ai.openai.api-key 以提供特定於聊天的 api-key |
- |
spring.ai.openai.chat.options.model |
要使用的 NVIDIA LLM 模型 |
- |
spring.ai.openai.chat.options.temperature |
用於控制生成完成的明顯創造性的取樣溫度。較高的值將使輸出更隨機,而較低的值將使結果更集中和確定。不建議在同一完成請求中修改溫度和 top_p,因為這兩個設定的相互作用難以預測。 |
0.8 |
spring.ai.openai.chat.options.frequencyPenalty |
介於 -2.0 和 2.0 之間的數字。正值會根據文字中現有頻率懲罰新令牌,從而降低模型重複相同行的可能性。 |
0.0f |
spring.ai.openai.chat.options.maxTokens |
在聊天補全中生成的最大令牌數。輸入令牌和生成令牌的總長度受模型上下文長度的限制。 |
注意:NVIDIA LLM API 要求顯式設定 |
spring.ai.openai.chat.options.n |
為每個輸入訊息生成多少個聊天完成選項。請注意,您將根據所有選項中生成的令牌數量收費。將 n 保持為 1 以最小化成本。 |
1 |
spring.ai.openai.chat.options.presencePenalty |
介於 -2.0 和 2.0 之間的數字。正值會根據新令牌是否出現在文字中來懲罰新令牌,從而增加模型討論新主題的可能性。 |
- |
spring.ai.openai.chat.options.responseFormat |
指定模型必須輸出的格式的物件。設定為 |
- |
spring.ai.openai.chat.options.seed |
此功能處於 Beta 階段。如果指定,我們的系統將盡力確定性地取樣,以便具有相同種子和引數的重複請求應返回相同的結果。 |
- |
spring.ai.openai.chat.options.stop |
API 將停止生成更多令牌的最多 4 個序列。 |
- |
spring.ai.openai.chat.options.topP |
除了使用溫度取樣之外的另一種方法,稱為核取樣,模型考慮具有 top_p 機率質量的令牌結果。因此 0.1 意味著只考慮佔前 10% 機率質量的令牌。我們通常建議更改此項或溫度,但不要同時更改兩者。 |
- |
spring.ai.openai.chat.options.tools |
模型可以呼叫的工具列表。目前,只支援函式作為工具。使用此項提供模型可以生成 JSON 輸入的函式列表。 |
- |
spring.ai.openai.chat.options.toolChoice |
控制模型呼叫哪個(如果有)函式。none 表示模型不會呼叫函式,而是生成一條訊息。auto 表示模型可以在生成訊息或呼叫函式之間進行選擇。透過 {"type: "function", "function": {"name": "my_function"}} 指定特定函式會強制模型呼叫該函式。當沒有函式存在時,none 是預設值。如果存在函式,auto 是預設值。 |
- |
spring.ai.openai.chat.options.user |
代表您的終端使用者的唯一識別符號,可以幫助 OpenAI 監控和檢測濫用。 |
- |
spring.ai.openai.chat.options.stream-usage |
(僅限流式傳輸)設定為新增一個額外的塊,其中包含整個請求的令牌使用統計資訊。此塊的 |
假 |
spring.ai.openai.chat.options.tool-names |
工具列表,透過其名稱標識,用於在單個提示請求中啟用函式呼叫。具有這些名稱的工具必須存在於 ToolCallback 登錄檔中。 |
- |
spring.ai.openai.chat.options.tool-callbacks |
要註冊到 ChatModel 的工具回撥。 |
- |
spring.ai.openai.chat.options.internal-tool-execution-enabled |
如果為 false,Spring AI 將不會在內部處理工具呼叫,而是將其代理到客戶端。然後,客戶端負責處理工具呼叫,將其分派到適當的函式,並返回結果。如果為 true(預設),Spring AI 將在內部處理函式呼叫。僅適用於支援函式呼叫的聊天模型 |
true |
所有以 spring.ai.openai.chat.options 為字首的屬性都可以在執行時透過向 Prompt 呼叫新增請求特定的 執行時選項 來覆蓋。 |
執行時選項
OpenAiChatOptions.java 提供了模型配置,例如要使用的模型、溫度、頻率懲罰等。
在啟動時,可以使用 OpenAiChatModel(api, options) 建構函式或 spring.ai.openai.chat.options.* 屬性配置預設選項。
在執行時,您可以透過向 Prompt 呼叫新增新的、請求特定的選項來覆蓋預設選項。例如,為特定請求覆蓋預設模型和溫度
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OpenAiChatOptions.builder()
.model("mixtral-8x7b-32768")
.temperature(0.4)
.build()
));| 除了模型特定的 OpenAiChatOptions,您還可以使用可移植的 ChatOptions 例項,該例項透過 ChatOptions#builder() 建立。 |
函式呼叫
NVIDIA LLM API 在選擇支援的模型時支援工具/函式呼叫。
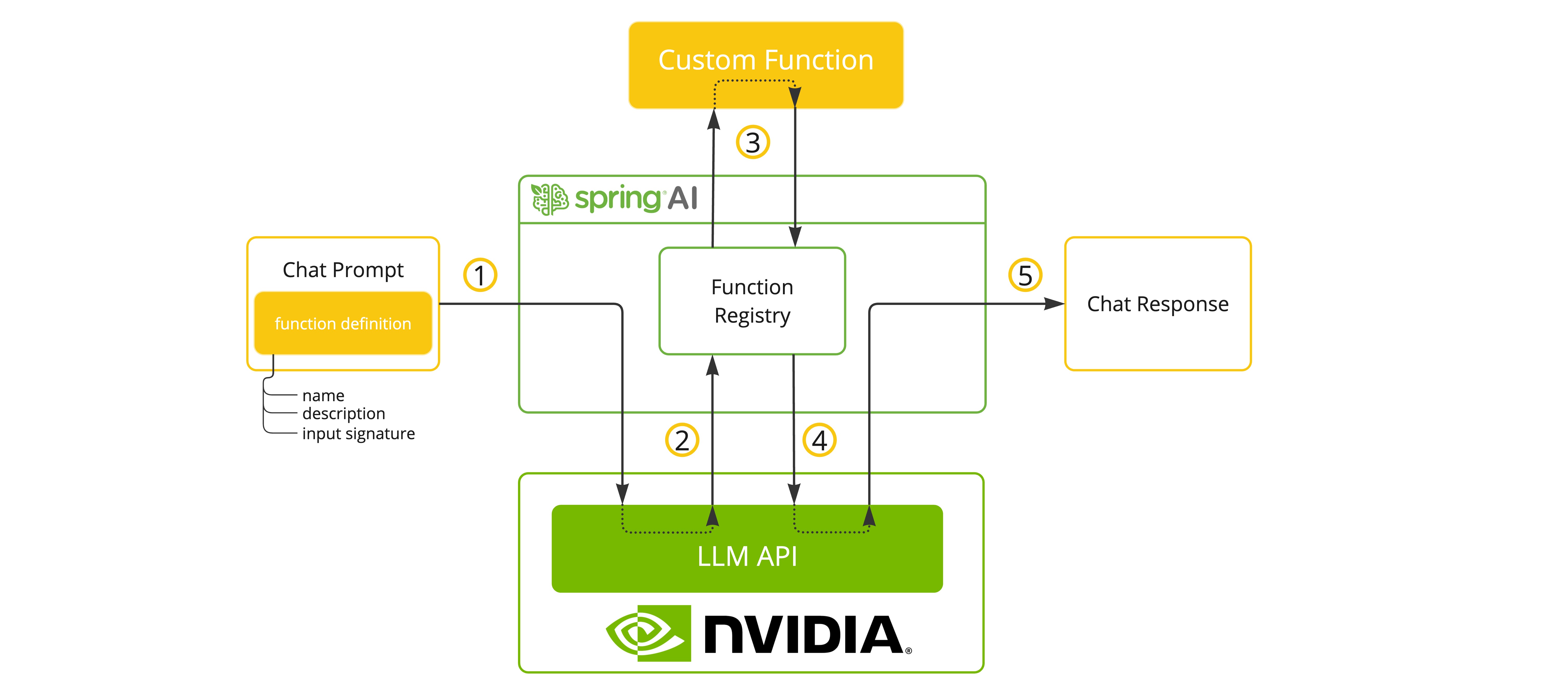
你可以向 ChatModel 註冊自定義 Java 函式,並讓提供的模型智慧地選擇輸出一個 JSON 物件,其中包含呼叫一個或多個已註冊函式的引數。這是一種將 LLM 功能與外部工具和 API 連線的強大技術。
工具示例
以下是使用 Spring AI 呼叫 NVIDIA LLM API 函式的簡單示例
spring.ai.openai.api-key=${NVIDIA_API_KEY}
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.options.model=meta/llama-3.1-70b-instruct
spring.ai.openai.chat.options.max-tokens=2048@SpringBootApplication
public class NvidiaLlmApplication {
public static void main(String[] args) {
SpringApplication.run(NvidiaLlmApplication.class, args);
}
@Bean
CommandLineRunner runner(ChatClient.Builder chatClientBuilder) {
return args -> {
var chatClient = chatClientBuilder.build();
var response = chatClient.prompt()
.user("What is the weather in Amsterdam and Paris?")
.functions("weatherFunction") // reference by bean name.
.call()
.content();
System.out.println(response);
};
}
@Bean
@Description("Get the weather in location")
public Function<WeatherRequest, WeatherResponse> weatherFunction() {
return new MockWeatherService();
}
public static class MockWeatherService implements Function<WeatherRequest, WeatherResponse> {
public record WeatherRequest(String location, String unit) {}
public record WeatherResponse(double temp, String unit) {}
@Override
public WeatherResponse apply(WeatherRequest request) {
double temperature = request.location().contains("Amsterdam") ? 20 : 25;
return new WeatherResponse(temperature, request.unit);
}
}
}在此示例中,當模型需要天氣資訊時,它將自動呼叫 weatherFunction bean,然後該 bean 可以獲取即時天氣資料。預期的響應如下:“阿姆斯特丹目前氣溫為 20 攝氏度,巴黎目前氣溫為 25 攝氏度。”
閱讀有關 OpenAI 函式呼叫 的更多資訊。
示例控制器
建立 一個新的 Spring Boot 專案,並將 spring-ai-starter-model-openai 新增到您的 pom(或 gradle)依賴項中。
在src/main/resources目錄下新增一個application.properties檔案,以啟用和配置 OpenAi 聊天模型
spring.ai.openai.api-key=${NVIDIA_API_KEY}
spring.ai.openai.base-url=https://integrate.api.nvidia.com
spring.ai.openai.chat.options.model=meta/llama-3.1-70b-instruct
# The NVIDIA LLM API doesn't support embeddings, so we need to disable it.
spring.ai.openai.embedding.enabled=false
# The NVIDIA LLM API requires this parameter to be set explicitly or server internal error will be thrown.
spring.ai.openai.chat.options.max-tokens=2048用你的 NVIDIA 憑據替換 api-key。 |
NVIDIA LLM API 要求顯式設定 max-token 引數,否則將丟擲伺服器錯誤。 |
這是一個使用聊天模型進行文字生成的簡單 @Controller 類的示例。
@RestController
public class ChatController {
private final OpenAiChatModel chatModel;
@Autowired
public ChatController(OpenAiChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}
