自定義查詢
Spring Data Neo4j,像所有其他 Spring Data 模組一樣,允許您在倉庫中指定自定義查詢。如果您無法透過派生查詢函式表達查詢邏輯,這些查詢就會派上用場。
由於 Spring Data Neo4j 在底層大量地以記錄為導向工作,因此重要的是要記住這一點,並且不要為同一個“根節點”構建多個記錄的結果集。
| 另請參閱常見問題解答,以瞭解從倉庫中使用自定義查詢的替代形式,特別是如何將自定義查詢與自定義對映一起使用:自定義查詢和自定義對映。 |
帶關係的查詢
警惕笛卡爾積
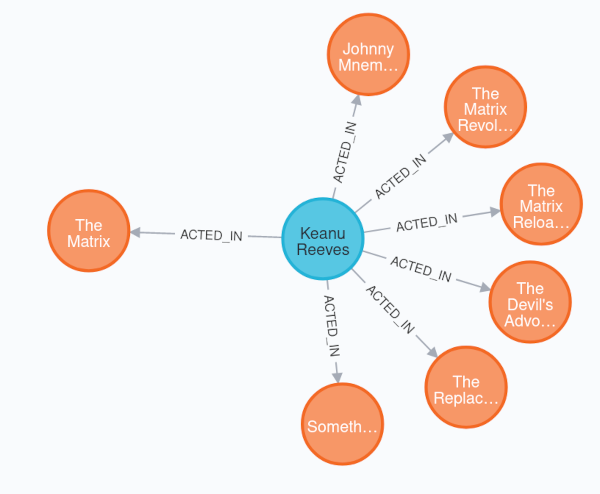
假設您有一個查詢,如 MATCH (m:Movie{title: 'The Matrix'})←[r:ACTED_IN]-(p:Person) return m,r,p,其結果類似於
+------------------------------------------------------------------------------------------+
| m | r | p |
+------------------------------------------------------------------------------------------+
| (:Movie) | [:ACTED_IN {roles: ["Emil"]}] | (:Person {name: "Emil Eifrem"}) |
| (:Movie) | [:ACTED_IN {roles: ["Agent Smith"]}] | (:Person {name: "Hugo Weaving}) |
| (:Movie) | [:ACTED_IN {roles: ["Morpheus"]}] | (:Person {name: "Laurence Fishburne"}) |
| (:Movie) | [:ACTED_IN {roles: ["Trinity"]}] | (:Person {name: "Carrie-Anne Moss"}) |
| (:Movie) | [:ACTED_IN {roles: ["Neo"]}] | (:Person {name: "Keanu Reeves"}) |
+------------------------------------------------------------------------------------------+
對映的結果很可能無法使用。如果將其對映到列表中,它將包含重複的 Movie,但此電影將只有一個關係。
為每個根節點獲取一條記錄
要獲取正確的物件,需要在查詢中 收集 關係和相關節點:MATCH (m:Movie{title: 'The Matrix'})←[r:ACTED_IN]-(p:Person) return m,collect(r),collect(p)
+------------------------------------------------------------------------+ | m | collect(r) | collect(p) | +------------------------------------------------------------------------+ | (:Movie) | [[:ACTED_IN], [:ACTED_IN], ...]| [(:Person), (:Person),...] | +------------------------------------------------------------------------+
透過將此結果作為單條記錄,Spring Data Neo4j 可以將所有相關節點正確新增到根節點。
深入圖譜
上面的示例假設您只嘗試獲取第一級相關節點。這有時是不夠的,圖譜中可能存在更深層的節點,這些節點也應該作為對映例項的一部分。有兩種方法可以實現這一點:資料庫端或客戶端減少。
為此,上面的示例還應包含返回初始 Movie 時 Persons 上的 Movies。
資料庫端減少
請記住,Spring Data Neo4j 只能正確地處理基於記錄的資料,一個實體例項的結果需要存在於一條記錄中。使用 Cypher 的路徑 功能是獲取圖譜中所有分支的有效選項。
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN p;這將導致多條路徑,這些路徑未合併到一條記錄中。可以呼叫 collect(p),但 Spring Data Neo4j 在對映過程中不理解路徑的概念。因此,需要提取節點和關係以用於結果。
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN m, nodes(p), relationships(p);由於存在多條從“駭客帝國”通向另一部電影的路徑,結果仍然不會是單條記錄。這就是 Cypher 的 reduce 函式 發揮作用的地方。
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
WITH collect(p) as paths, m
WITH m,
reduce(a=[], node in reduce(b=[], c in [aa in paths | nodes(aa)] | b + c) | case when node in a then a else a + node end) as nodes,
reduce(d=[], relationship in reduce(e=[], f in [dd in paths | relationships(dd)] | e + f) | case when relationship in d then d else d + relationship end) as relationships
RETURN m, relationships, nodes;reduce 函式允許我們扁平化來自各種路徑的節點和關係。結果我們將得到一個類似於 為每個根節點獲取一條記錄 的元組,但集合中混合了關係型別或節點。
客戶端減少
如果需要在客戶端進行減少,Spring Data Neo4j 使您能夠對映關係或節點的列表的列表。然而,返回的記錄應包含所有資訊以正確地水合(hydrate)結果實體例項的要求仍然適用。
MATCH p=(m:Movie{title: 'The Matrix'})<-[:ACTED_IN]-(:Person)-[:ACTED_IN*..0]->(:Movie)
RETURN m, collect(nodes(p)), collect(relationships(p));額外的 collect 語句建立以下格式的列表
[[rel1, rel2], [rel3, rel4]]
這些列表現在將在對映過程中轉換為扁平列表。
是選擇客戶端減少還是資料庫端減少取決於將生成的資料量。當使用 reduce 函式時,所有路徑都需要首先在資料庫記憶體中建立。另一方面,大量需要在客戶端合併的資料會導致客戶端記憶體使用量增加。 |
使用路徑填充並返回實體列表
給定一個圖,它看起來像這樣

以及如 對映 中所示的領域模型(為簡潔起見,已省略建構函式和訪問器)
@Node
public class SomeEntity {
@Id
private final Long number;
private String name;
@Relationship(type = "SOME_RELATION_TO", direction = Relationship.Direction.OUTGOING)
private Set<SomeRelation> someRelationsOut = new HashSet<>();
}
@RelationshipProperties
public class SomeRelation {
@RelationshipId
private Long id;
private String someData;
@TargetNode
private SomeEntity targetPerson;
}如您所見,關係僅是出站的。生成的查詢器方法(包括 findById)將始終嘗試匹配要對映的根節點。從那裡開始,所有相關物件都將被對映。在只應返回一個物件的查詢中,將返回該根物件。在返回許多物件的查詢中,將返回所有匹配的物件。從這些返回的物件中出站和入站的關係當然會被填充。
假設有以下 Cypher 查詢
MATCH p = (leaf:SomeEntity {number: $a})-[:SOME_RELATION_TO*]-(:SomeEntity)
RETURN leaf, collect(nodes(p)), collect(relationships(p))它遵循 為每個根節點獲取一條記錄 的建議,並且對於您想要在此處匹配的葉節點非常有效。然而:這僅適用於返回 0 或 1 個對映物件的所有場景。雖然該查詢將像以前一樣填充所有關係,但它不會返回所有 4 個物件。
這可以透過返回整個路徑來改變
MATCH p = (leaf:SomeEntity {number: $a})-[:SOME_RELATION_TO*]-(:SomeEntity)
RETURN p在這裡,我們確實希望利用路徑 p 實際上返回 3 行帶有通向所有 4 個節點的路徑的事實。所有 4 個節點都將被填充、連結並返回。
自定義查詢中的引數
您可以使用 $ 語法(從 Neo4j 4.0 開始,Cypher 引數的舊 ${foo} 語法已從資料庫中刪除),以與在 Neo4j Browser 或 Cypher-Shell 中發出的標準 Cypher 查詢完全相同的方式進行操作。
public interface ARepository extends Neo4jRepository<AnAggregateRoot, String> {
@Query("MATCH (a:AnAggregateRoot {name: $name}) RETURN a") (1)
Optional<AnAggregateRoot> findByCustomQuery(String name);
}| 1 | 這裡我們按名稱引用引數。您也可以使用 $0 等代替。 |
您需要使用 -parameters 編譯您的 Java 8+ 專案,以便命名引數無需進一步註釋即可工作。Spring Boot Maven 和 Gradle 外掛會自動為您執行此操作。如果由於任何原因不可行,您可以新增 @Param 並明確指定名稱,或使用引數索引。 |
作為引數傳遞給帶有自定義查詢註解的函式的對映實體(所有帶有 @Node 的實體)將被轉換為巢狀對映。以下示例表示 Neo4j 引數的結構。
給定 Movie、Vertex 和 Actor 類,按 電影模型 所示進行註解
@Node
public final class Movie {
@Id
private final String title;
@Property("tagline")
private final String description;
@Relationship(value = "ACTED_IN", direction = Direction.INCOMING)
private final List<Actor> actors;
@Relationship(value = "DIRECTED", direction = Direction.INCOMING)
private final List<Person> directors;
}
@Node
public final class Person {
@Id @GeneratedValue
private final Long id;
private final String name;
private Integer born;
@Relationship("REVIEWED")
private List<Movie> reviewed = new ArrayList<>();
}
@RelationshipProperties
public final class Actor {
@RelationshipId
private final Long id;
@TargetNode
private final Person person;
private final List<String> roles;
}
interface MovieRepository extends Neo4jRepository<Movie, String> {
@Query("MATCH (m:Movie {title: $movie.__id__})\n"
+ "MATCH (m) <- [r:DIRECTED|REVIEWED|ACTED_IN] - (p:Person)\n"
+ "return m, collect(r), collect(p)")
Movie findByMovie(@Param("movie") Movie movie);
}將 Movie 例項傳遞給上面的倉庫方法將生成以下 Neo4j 對映引數
{
"movie": {
"__labels__": [
"Movie"
],
"__id__": "The Da Vinci Code",
"__properties__": {
"ACTED_IN": [
{
"__properties__": {
"roles": [
"Sophie Neveu"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 402,
"__properties__": {
"name": "Audrey Tautou",
"born": 1976
}
}
},
{
"__properties__": {
"roles": [
"Sir Leight Teabing"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 401,
"__properties__": {
"name": "Ian McKellen",
"born": 1939
}
}
},
{
"__properties__": {
"roles": [
"Dr. Robert Langdon"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 360,
"__properties__": {
"name": "Tom Hanks",
"born": 1956
}
}
},
{
"__properties__": {
"roles": [
"Silas"
]
},
"__target__": {
"__labels__": [
"Person"
],
"__id__": 403,
"__properties__": {
"name": "Paul Bettany",
"born": 1971
}
}
}
],
"DIRECTED": [
{
"__labels__": [
"Person"
],
"__id__": 404,
"__properties__": {
"name": "Ron Howard",
"born": 1954
}
}
],
"tagline": "Break The Codes",
"released": 2006
}
}
}節點由對映表示。該對映將始終包含 __id__,即對映的 id 屬性。在 __labels__ 下,所有標籤(靜態和動態)都將可用。所有屬性和關係型別都將出現在這些對映中,就像實體由 SDN 寫入時在圖譜中出現一樣。值將具有正確的 Cypher 型別,無需進一步轉換。
所有關係都是對映列表。動態關係將相應地解析。一對一關係也將序列化為單例列表。因此,要訪問人與人之間的一對一對映,您可以編寫 $person.__properties__.BEST_FRIEND[0].__target__.__id__。 |
如果一個實體與不同型別的其他節點具有相同型別的關係,它們都將出現在同一個列表中。如果您需要這樣的對映並且還需要處理這些自定義引數,則必須相應地展開它。一種方法是相關子查詢(需要 Neo4j 4.1+)。
自定義查詢中的值表示式
自定義查詢中的 Spring Expression Language
Spring Expression Language (SpEL) 可以在自定義查詢中用於 :#{} 內部。這裡的冒號指的是一個引數,這樣的表示式應該在引數有意義的地方使用。然而,當使用我們的 字面量擴充套件 時,您可以在標準 Cypher 不允許引數的地方(例如標籤或關係型別)使用 SpEL 表示式。這是 Spring Data 定義查詢中一段文字的標準方式,該文字將進行 SpEL 評估。
以下示例基本定義了與上面相同的查詢,但使用 WHERE 子句以避免更多的大括號
public interface ARepository extends Neo4jRepository<AnAggregateRoot, String> {
@Query("MATCH (a:AnAggregateRoot) WHERE a.name = :#{#pt1 + #pt2} RETURN a")
Optional<AnAggregateRoot> findByCustomQueryWithSpEL(String pt1, String pt2);
}SpEL 塊以 :#{ 開始,然後按名稱 (#pt1) 引用給定的 String 引數。不要與上面的 Cypher 語法混淆!SpEL 表示式將兩個引數連線成一個單一值,最終傳遞給 appendix/neo4j-client.adoc#neo4j-client。SpEL 塊以 } 結束。
SpEL 還解決了另外兩個問題。我們提供了兩個擴充套件,允許將 Sort 物件傳遞給自定義查詢。還記得 faq.adoc#custom-queries-with-page-and-slice-examples 來自 自定義查詢 嗎?透過 orderBy 擴充套件,您可以將帶有動態排序的 Pageable 傳遞給自定義查詢
import org.springframework.data.domain.Pageable;
import org.springframework.data.domain.Sort;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
public interface MyPersonRepository extends Neo4jRepository<Person, Long> {
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ ":#{orderBy(#pageable)} SKIP $skip LIMIT $limit" (1)
)
Slice<Person> findSliceByName(String name, Pageable pageable);
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n :#{orderBy(#sort)}" (2)
)
List<Person> findAllByName(String name, Sort sort);
}| 1 | Pageable 在 SpEL 上下文中始終具有名稱 pageable。 |
| 2 | Sort 在 SpEL 上下文中始終具有名稱 sort。 |
Spring 表示式語言擴充套件
字面量擴充套件
literal 擴充套件可用於在自定義查詢中使標籤或關係型別等內容“動態化”。Cypher 中既不能引數化標籤也不能引數化關係型別,因此它們必須以字面量形式給出。
interface BaseClassRepository extends Neo4jRepository<Inheritance.BaseClass, Long> {
@Query("MATCH (n:`:#{literal(#label)}`) RETURN n") (1)
List<Inheritance.BaseClass> findByLabel(String label);
}| 1 | literal 擴充套件將被評估引數的字面值替換。 |
這裡,literal 值已用於動態匹配標籤。如果您將 SomeLabel 作為引數傳遞給該方法,則將生成 MATCH (n:。已新增反引號以正確轉義值。SDN 不會為您執行此操作,因為在所有情況下這可能不是您想要的。SomeLabel) RETURN n
列表擴充套件
對於多個值,存在 allOf 和 anyOf,它們將分別渲染一個 & 或 | 連線的所有值列表。
interface BaseClassRepository extends Neo4jRepository<Inheritance.BaseClass, Long> {
@Query("MATCH (n:`:#{allOf(#label)}`) RETURN n")
List<Inheritance.BaseClass> findByLabels(List<String> labels);
@Query("MATCH (n:`:#{anyOf(#label)}`) RETURN n")
List<Inheritance.BaseClass> findByLabels(List<String> labels);
}引用標籤
您已經知道如何將節點對映到領域物件
@Node(primaryLabel = "Bike", labels = {"Gravel", "Easy Trail"})
public class BikeNode {
@Id String id;
String name;
}這個節點有幾個標籤,在自定義查詢中一直重複它們很容易出錯:您可能會忘記一個或打錯字。我們提供以下表達式來緩解這種情況:#{#staticLabels}。請注意,這個表示式不以冒號開頭!您可以在帶有 @Query 註解的倉庫方法中使用它
#{#staticLabels} 的實際應用public interface BikeRepository extends Neo4jRepository<Bike, String> {
@Query("MATCH (n:#{#staticLabels}) WHERE n.id = $nameOrId OR n.name = $nameOrId RETURN n")
Optional<Bike> findByNameOrId(@Param("nameOrId") String nameOrId);
}此查詢將解析為
MATCH (n:`Bike`:`Gravel`:`Easy Trail`) WHERE n.id = $nameOrId OR n.name = $nameOrId RETURN n請注意我們如何使用標準引數來表示 nameOrId:在大多數情況下,無需透過新增 SpEL 表示式來使事情複雜化。

