Spring 資料整合之旅的簡史
Spring 在資料整合方面的旅程始於 Spring Integration。憑藉其程式設計模型,它提供了統一的開發體驗,用於構建能夠採用 企業整合模式 的應用程式,以連線到外部系統,例如資料庫、訊息代理等。
快進到雲時代,微服務在企業環境中變得突出。Spring Boot 改變了開發人員構建應用程式的方式。憑藉 Spring 的程式設計模型和 Spring Boot 處理的執行時職責,開發獨立的、生產級的基於 Spring 的微服務變得無縫。
為了將其擴充套件到資料整合工作負載,Spring Integration 和 Spring Boot 被組合到一個新專案中。Spring Cloud Stream 誕生了。
使用 Spring Cloud Stream,開發人員可以
-
獨立構建、測試和部署以資料為中心的應用程式。
-
應用現代微服務架構模式,包括透過訊息傳遞進行組合。
-
透過以事件為中心的思維解耦應用程式職責。事件可以表示在時間上發生的事情,下游消費者應用程式可以對其做出反應,而無需知道它的來源或生產者的身份。
-
將業務邏輯移植到訊息代理(如 RabbitMQ、Apache Kafka、Amazon Kinesis)。
-
依靠框架的自動內容型別支援來處理常見用例。擴充套件到不同的資料轉換型別是可能的。
-
等等。
快速入門
您可以按照此三步指南,在不到 5 分鐘的時間內嘗試 Spring Cloud Stream,甚至在您深入瞭解任何細節之前。
我們將向您展示如何建立一個 Spring Cloud Stream 應用程式,該應用程式接收來自您選擇的訊息中介軟體(稍後詳述)的訊息,並將接收到的訊息記錄到控制檯。我們稱之為 LoggingConsumer。雖然不實用,但它很好地介紹了 Spring Cloud Stream 的一些主要概念和抽象,使其更容易理解本使用者指南的其餘部分。
這三個步驟如下:
使用 Spring Initializr 建立示例應用程式
首先,訪問 Spring Initializr。從那裡,您可以生成我們的 LoggingConsumer 應用程式。要這樣做
-
在 依賴項 部分,開始鍵入
stream。當出現“Cloud Stream”選項時,選擇它。 -
開始鍵入“kafka”或“rabbit”。
-
選擇“Kafka”或“RabbitMQ”。
基本上,您選擇應用程式繫結的訊息中介軟體。我們建議使用您已經安裝或更喜歡安裝和執行的那個。此外,從 Initializr 螢幕上您可以看到,還有一些其他選項可供選擇。例如,您可以選擇 Gradle 作為構建工具而不是 Maven(預設)。
-
在 Artifact 欄位中,鍵入 'logging-consumer'。
Artifact 欄位的值成為應用程式名稱。如果您選擇 RabbitMQ 作為中介軟體,您的 Spring Initializr 現在應該如下所示
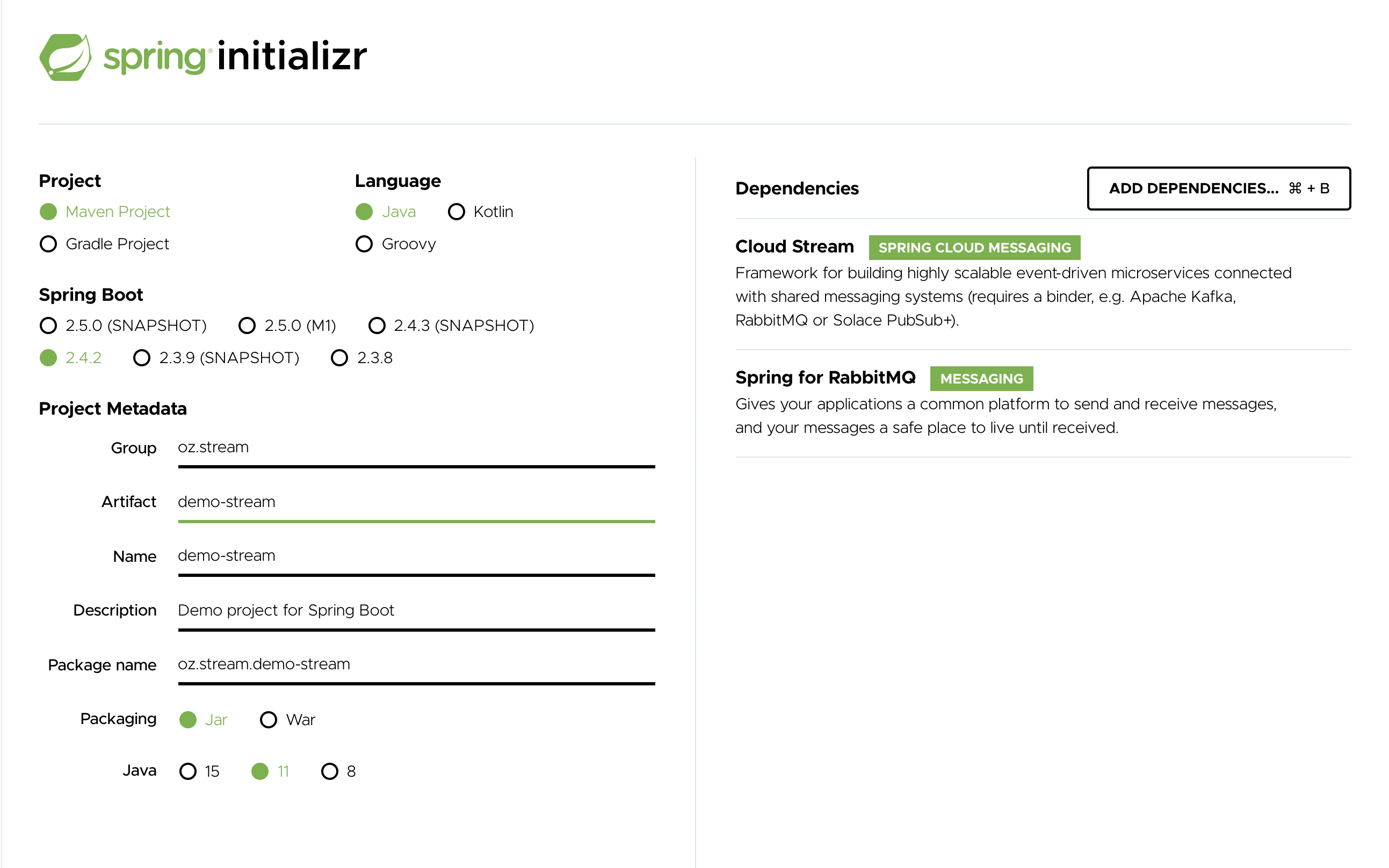
-
點選 生成專案 按鈕。
這樣做會將生成的專案的壓縮版本下載到您的硬碟。
-
將檔案解壓縮到您要用作專案目錄的資料夾中。
| 我們鼓勵您探索 Spring Initializr 中可用的許多可能性。它允許您建立許多不同型別的 Spring 應用程式。 |
將專案匯入您的 IDE
現在您可以將專案匯入您的 IDE。請記住,根據 IDE 的不同,您可能需要遵循特定的匯入過程。例如,根據專案生成方式(Maven 或 Gradle),您可能需要遵循特定的匯入過程(例如,在 Eclipse 或 STS 中,您需要使用檔案 → 匯入 → Maven → 現有 Maven 專案)。
匯入後,專案不得有任何型別的錯誤。此外,src/main/java 應該包含 com.example.loggingconsumer.LoggingConsumerApplication。
從技術上講,此時您可以執行應用程式的主類。它已經是有效的 Spring Boot 應用程式。但是,它不做任何事情,所以我們想新增一些程式碼。
新增訊息處理程式、構建和執行
修改 com.example.loggingconsumer.LoggingConsumerApplication 類,使其看起來如下所示
@SpringBootApplication
public class LoggingConsumerApplication {
public static void main(String[] args) {
SpringApplication.run(LoggingConsumerApplication.class, args);
}
@Bean
public Consumer<Person> log() {
return person -> {
System.out.println("Received: " + person);
};
}
public static class Person {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String toString() {
return this.name;
}
}
}從前面的列表中可以看出
-
我們使用函數語言程式設計模型(參見 [Spring Cloud Function support])將單個訊息處理程式定義為
Consumer。 -
我們依賴框架約定將此類處理程式繫結到由繫結器公開的輸入目標繫結。
這樣做還可以讓您看到框架的一個核心功能:它嘗試自動將傳入訊息負載轉換為 Person 型別。
您現在擁有一個功能齊全的 Spring Cloud Stream 應用程式,它偵聽訊息。為了簡單起見,我們假設您在 第一步 中選擇了 RabbitMQ。假設您已安裝並執行 RabbitMQ,您可以透過在 IDE 中執行其 main 方法來啟動應用程式。
您應該會看到以下輸出
--- [ main] c.s.b.r.p.RabbitExchangeQueueProvisioner : declaring queue for inbound: input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg, bound to: input
--- [ main] o.s.a.r.c.CachingConnectionFactory : Attempting to connect to: [localhost:5672]
--- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#2a3a299:0/SimpleConnection@66c83fc8. . .
. . .
--- [ main] o.s.i.a.i.AmqpInboundChannelAdapter : started inbound.input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg
. . .
--- [ main] c.e.l.LoggingConsumerApplication : Started LoggingConsumerApplication in 2.531 seconds (JVM running for 2.897)轉到 RabbitMQ 管理控制檯或任何其他 RabbitMQ 客戶端,並向 input.anonymous.CbMIwdkJSBO1ZoPDOtHtCg 傳送訊息。anonymous.CbMIwdkJSBO1ZoPDOtHtCg 部分表示組名,它是生成的,因此在您的環境中必然不同。為了更具可預測性,您可以透過設定 spring.cloud.stream.bindings.input.group=hello(或任何您喜歡的名稱)來使用顯式組名。
訊息的內容應該是 Person 類的 JSON 表示,如下所示
{"name":"Sam Spade"}
然後,在您的控制檯中,您應該會看到
收到:Sam Spade
您還可以將應用程式構建並打包成一個引導 JAR(使用 ./mvnw clean install),然後使用 java -jar 命令執行構建的 JAR。
現在您有了一個正在執行的(儘管非常基礎的)Spring Cloud Stream 應用程式。
流資料上下文中的 Spring 表示式語言 (SpEL)
在整個參考手冊中,您將遇到許多可以利用 Spring 表示式語言 (SpEL) 的功能和示例。理解使用它時某些限制是很重要的。
SpEL 允許您訪問當前訊息以及您正在執行的應用程式上下文。但是,重要的是要了解 SpEL 可以看到的資料型別,尤其是在傳入訊息的上下文中。從代理,訊息以 byte[] 的形式到達。然後,它由繫結器轉換為 Message<byte[]>,而您可以看到訊息的有效負載保持其原始形式。訊息的標頭是 <String, Object>,其中值通常是另一個原始型別或原始型別的集合/陣列,因此是 Object。這是因為繫結器不知道所需的輸入型別,因為它無法訪問使用者程式碼(函式)。所以,實際上繫結器傳遞了一個帶有有效負載和一些可讀元資料(以訊息標頭形式)的信封,就像透過郵件遞送的信件一樣。這意味著,雖然可以訪問訊息的有效負載,但您只能將其作為原始資料(即 byte[])訪問。而且,雖然開發人員可能經常要求 SpEL 能夠以具體型別(例如 Foo、Bar 等)訪問有效負載物件的欄位,但您可以看到實現起來有多麼困難甚至不可能。這裡有一個示例來演示這個問題;想象一下您有一個路由表示式,根據有效負載型別路由到不同的函式。這個要求意味著有效負載從 byte[] 轉換為特定型別,然後應用 SpEL。但是,為了執行這種轉換,我們需要知道要傳遞給轉換器的實際型別,而這來自函式的簽名,我們不知道是哪個函式。解決此要求的一個更好的方法是將型別資訊作為訊息標頭傳遞(例如,application/json;type=foo.bar.Baz)。您將獲得一個清晰可讀的字串值,可以在一年中輕鬆訪問和評估,並且易於閱讀的 SpEL 表示式。
此外,將有效負載用於路由決策被認為是非常糟糕的做法,因為有效負載被認為是特權資料——只有其最終接收者才能讀取的資料。同樣,以郵件遞送類比,您不會希望郵遞員開啟您的信封並閱讀信件內容以做出一些遞送決策。同樣的道理也適用於這裡,尤其是在生成訊息時包含此類資訊相對容易的情況下。它強制執行與透過網路傳輸的資料設計相關的特定級別的紀律,以及這些資料中哪些部分可以被視為公開的,哪些是特權的。

